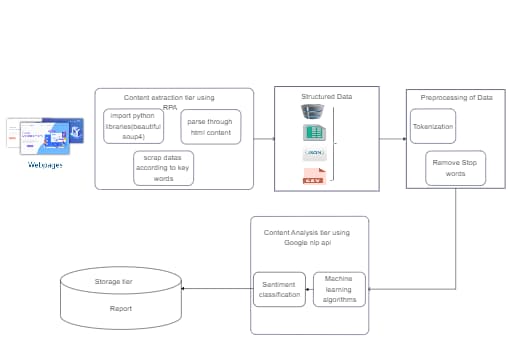
This Web Content Analysis Workflow diagram illustrates the process of extracting, preprocessing, and analyzing web data. The workflow begins with content extraction using Python libraries like Beautiful Soup and RPA for parsing HTML content. Structured data in formats like JSON or CSV is then preprocessed by tokenization and removing stop words. The final analysis uses tools like Google NLP API for sentiment classification and machine learning algorithms. Ideal for developers, data analysts, and researchers, this EdrawMax template simplifies the visualization of data workflows.