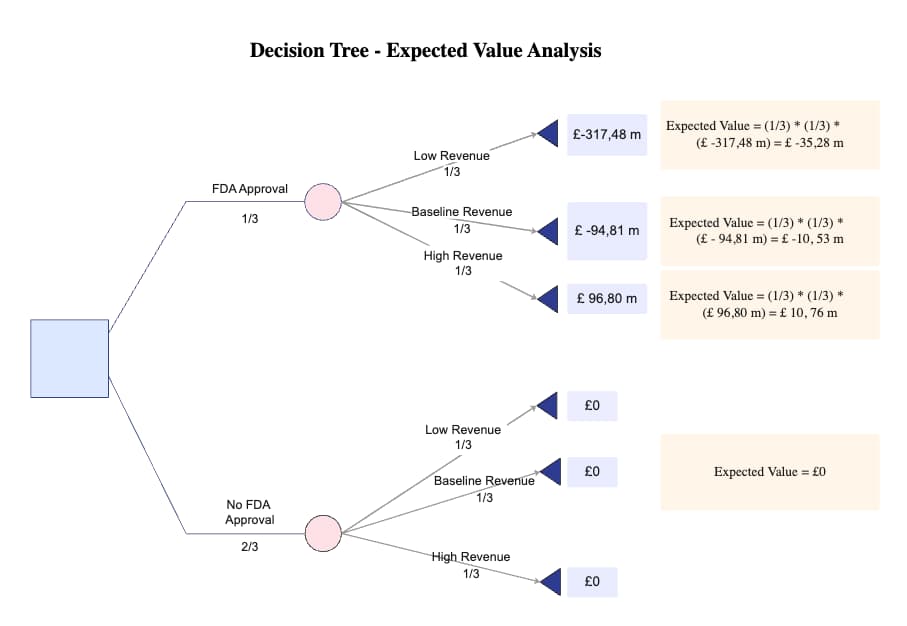
This is a decision tree for expected value analysis. It displays a tree-like structure, where each node represents a feature or attribute of the data, and each branch represents a decision made based on that feature. The endpoints of the tree represent the final classification or regression result. It can be used to find the optimal decision path for each data point by splitting the data based on different features.



 Desktop
Desktop