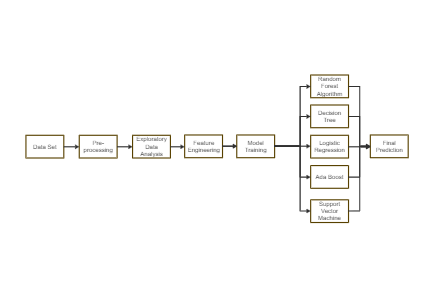
The provided image illustrates a flowchart outlining the standard process in machine learning. The flowchart begins with 'Data Set', indicating the initial step of obtaining a dataset. The next step is 'Pre-processing', which typically involves cleaning and preparing the data for analysis. Following this is 'Exploratory Data Analysis', where data is explored to find patterns or initial insights. 'Feature Engineering' comes next, representing the process of creating new input features from existing ones to improve model performance. 'Model Training' is the subsequent phase, where algorithms learn from the data. This phase branches into different machine learning algorithms: 'Random Forest Algorithm', 'Decision Tree', 'Logistic Regression', 'Ada Boost', and 'Support Vector Machine'. Each algorithm represents a different approach to modeling the data. The final step is 'Final Prediction', where the outcome or decision is made based on the model's learning. This flowchart is a high-level representation of the machine learning pipeline, highlighting key stages and multiple algorithmic approaches before reaching a prediction.



 Desktop
Desktop